



A Developer’s Guide to the zkGalaxy
Introduction
Last summer, Vitalik wrote a blog post outlining the different types of zkEVMs (zero knowledge Ethereum virtual machines). He defined them along the trade-off axes of performance and compatibility.

Low-level zk Development
Arkworks-rs
Arkworks-rs is an ecosystem of Rust libraries that provides efficient and secure implementations of the subcomponents of a zkSNARK application. Arkworks provides the interfaces necessary for developers to customize the software stack for a zk application without having to re-implement commonalities with other existing libraries.
Before Arkworks, the only way to create a new zk application was to build everything from scratch. The key advantages of Arkworks-rs over custom-built, vertically integrated tools are the level of flexibility, the reduction in duplicated engineering, and the reduction in auditing effort. Arkworks’ sensible interface lines between components allow for a pace of upgradability that can keep the stack relevant amidst the blistering pace of innovation in zk technologies, without forcing teams to rebuild everything from scratch.
Who is it for?
Arkworks is for projects that need fine control over the entire zk software stack, but do not want to build all the redundant pieces from scratch. If you are considering a custom version of a circuit DSL because, for example, you are prototyping a new proof system but are unsure of the commitment scheme or corresponding elliptic curve, arkworks will allow you to rapidly swap between several options with shared interfaces, rather than starting from scratch.
Pros
- Flexibility through modularity
- Less duplication of code
- Lower engineering cost
- Reduced audit/bug surface area
- Upgrade any component without major refactoring
- Easy to experiment with new primitives in a rapidly evolving zk environment
Cons
- Requires deep understanding of the full software stack
- Too much control can lead to foot guns if not properly understood
- Granular control requires expertise at all levels of the stack
- Arkworks does provide some sensible defaults.
zk Domain Specific Languages (DSL)
In order to create a proof about some computation, first this computation must be expressed in a form that a zkSNARK system can understand. Several domain specific languages have created programming languages that allow application developers to express their computation in such a way. These include Aztec Noir, Starknet’s Cairo, Circom, ZoKrates, and Aleo’s Leo among others. The underlying proof system and mathematical details are generally not exposed to the application developer.
The Developer Experience
zkApp developers must become proficient in writing their programs in domain-specific languages. Some of these languages look a lot like familiar programming languages, while others can be quite difficult to learn. Let’s break down a few of these:
Cairo – Starkware DSL necessary for building apps on Starknet. Compiles down into Cairo-specific assembly language that can be interpreted by the Cairo zkVM.
ZoKrates — ZoKrates is a toolkit for common SNARK needs including a high-level language to write circuits. ZoKrates also has some flexibility around the curves, proving scheme, and backend, allowing devs to hot-swap by simple CLI argument.
Circom — Circom is a purpose-built language for constructing circuits. Currently, it is the de-facto language for circuits in production. The language is not especially ergonomic. The language itself makes you acutely aware of the fact that you are writing circuits.
Leo — Leo was developed as the language for the Aleo blockchain. Leo has some Rust-like syntax and is specifically made for state transitions inside of a blockchain.
Noir – Rust-inspired syntax. Architected around the IR rather than the language itself, which means that it can have an arbitrary frontend.

Who is it for?
Any application developer who wants to take advantage of the unique properties of zk in their application. Some of these languages have been battle tested with billions of dollars moving across them via chains like ZCash and Starknet. While some of the projects we will discuss are not quite ready for production use, writing your circuits in one of these languages is currently the best strategy, unless you need the finer controls that a toolkit like Arkworks provides.
Pros
- Users don’t need to understand the underlying zk details
- Available today with some production experience
- Verifiable on chain
- Ecosystem agnostic
Cons
- Users need to learn a new DSL
- Siloed tooling and support around each of these languages
- Little to no control over the underlying proving stack (for now)
zkEVMs
The primary goal of a zkEVM is to take an Ethereum state transition and prove its validity using a succinct zero knowledge proof of correctness. As mentioned in Vitalik’s post, there are a number of ways to do this with subtle differences and corresponding trade-offs.
The main technical difference between all of these is exactly where in the language stack the computation is converted into a form (arithmetization) that can be used in a proving system. In some zkEVMs, this happens at the high-level languages (Solidity, Vyper, Yul), while other approaches attempt to prove the EVM all the way to the opcode level. The tradeoffs between these approaches were covered deeply in Vitalik’s post, but I will summarize it in one sentence: The lower the conversion/arithmetization happens in the stack, the larger the performance penalty.

Why are the EVM opcodes expensive to prove in zk?
The main challenge with creating proofs for a virtual machine is that the size of the circuit grows proportionally to the size of ALL possible instructions for every executed instruction. This occurs because the circuit does not know what instructions will be executed in each program, so it needs to support all of them.
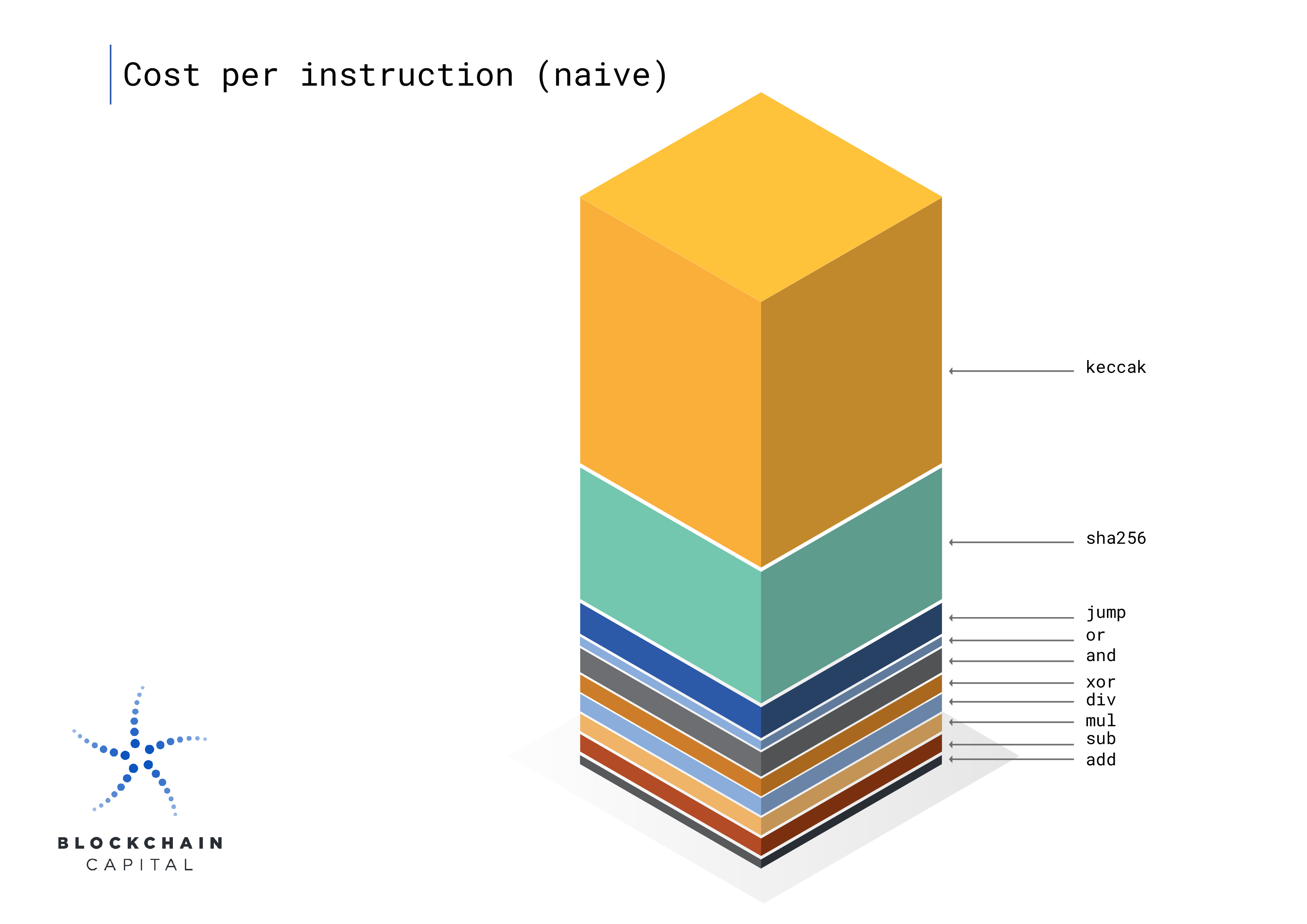
What this means in practice is that you pay (in performance cost) for the most expensive possible instruction, even when you are only executing the simplest instruction. This leads to a direct trade-off between generalizability and performance–as you add more instructions for generalizability, you pay for this on every instruction you prove!
This is a fundamental problem with universal circuits, but with new developments in technologies like IVC (incremental verifiable compute), this limitation can be ameliorated by breaking the computation into smaller chunks that each have specialized, smaller subcircuits.
Today’s zkEVM implementations use different strategies to mitigate the impact of this issue… For example, zkSync rips out the more expensive operations (mostly cryptographic pre-compiles like hashes and ECDSA) from the main execution proving circuit into separate circuits that are aggregated together at the end via snark recursion. zkSync took this approach after they realized that the majority of their costs were coming from a few complex instructions.

At the core, the reason that proving a more EVM-equivalent instruction set is more expensive is that the EVM was not designed for zk computations. Abandoning the EVM earlier in the stack allows zkEVMs to run on instruction sets that are more optimized for zk, and thus cheaper to prove.
Who is it for?
The ideal customers for a zkEVM are smart contract applications that need orders of magnitude cheaper transactions than what is available on L1 Ethereum. These developers don’t necessarily have the expertise or bandwidth to write zk applications from scratch. Therefore, they prefer to write their applications in higher-level languages they are familiar with, like Solidity.
Why are so many teams building this?
Scaling Ethereum is currently the most demanded application of zk technology.
A zkEVM is an Ethereum scaling solution that frictionlessly mitigates the congestion issue that restricts L1 dApp developers.
The Developer experience
The goal of a zkEVM is to support a developer experience that is as close as possible to current Ethereum development. Full Solidity support means that teams don’t have to build and maintain multiple codebases. This is somewhat impractical to do perfectly because zkEVMs need to trade off some compatibility to be able to generate proofs of reasonable size in a reasonable amount of time.
Quick Case study: zkSync vs Scroll
The primary difference between zkSync and Scroll is where/when in the stack they perform arithmetization – that is, where they convert from normal EVM constructs into a SNARK-friendly representation. For zkSync, this happens when they convert the YUL bytecode into their own custom zk instruction set. For Scroll, this happens at the end, when the actual execution trace is generated with actual EVM opcodes.
So, for zkSync, everything is the same as interacting with the EVM until the zk bytecode is generated. For Scroll, everything is the same until the actual bytecode is executed. This is a subtle difference, which trades off performance for support. For example, zkSync will not support EVM bytecode tools like a debugger out of the box, because it is a completely different bytecode. While Scroll will have more difficulty getting good performance out of an instruction set, that was not designed for zk. There are pros and cons to both strategies and ultimately there are a lot of exogenous factors that will impact their relative success.
zkLLVM Circuit Compiler
Despite its naming, LLVM is not a VM (virtual machine). LLVM is the name of a set of compiler tools that is anchored by an intermediate representation (IR) that is language agnostic.
=nil; Foundation (about the name, it’s a SQL injection joke if you’re wondering) is building a compiler that can convert any LLVM frontend language into an intermediate representation that can be proven within a SNARK. The zkLLVM is architected as an extension to the existing LLVM infrastructure, an industry-standard toolchain that supports many high-level languages like Rust, C, C++ etc.
How it works

A user who wants to prove some computation would simply implement that computation in C++. The zkLLVM takes this high-level source code that is supported by their modified clang compiler (currently C++) and generates some intermediate representation of the circuit. At this point, the circuit is ready to be proven, but the user may want to prove the circuit based on some dynamic inputs. To handle dynamic inputs, the zkLLVM has an additional component referred to as the assigner, which generates an assignment table with all the inputs and witnesses fully preprocessed and ready to be proven alongside the circuit.
These 2 components are all that is necessary to generate a proof. A user can theoretically generate a proof themselves, but since this is a somewhat specialized computational task, they may want to pay someone else, who has the hardware, to do it for them. For this counterparty discovery mechanism, =nil; Foundation has also established a ‘proof market’ where provers vie to prove computation for users who will pay them to do so. This free market dynamic will lead to provers optimizing the most valuable proving tasks.
Trade-offs
Since every computational task to be proven is unique and generates a different circuit, there are an infinite number of circuits that provers will need to be able to handle. This forced generalizability makes the optimization of individual circuits difficult. The introduction of a proof market allows specialization on the circuits that the market deems valuable. Without this market, it would be challenging to convince a prover to optimize this circuit because of this natural cold start problem.
The other trade-off is the classic abstraction vs. control. Users that are willing to take this easy-to-use interface are giving up control over the underlying cryptographic primitives. For many users, this is a very valid trade-off to make, as it is often better to let the cryptography experts make these decisions for you.
Pros
- Users can write code in familiar high level languages
- All zk internals are abstracted away from the users
- Doesn’t rely on a specific ‘VM’ circuit that adds additional overhead
Cons
- Every program has a different circuit. Difficult to optimize. (proof market partially solves this)
- Non-trivial to swap/upgrade internal zk libraries (requires forking)
zkVM
A zkVM describes the superset of all zk virtual machines, while a zkEVM is a specific type of zkVM, which was worth discussing as a separate topic because of its prevalence today. There are a few other projects that are working on building more generalized zkVMs that are based on ISAs besides the bespoke crypto VMs.
Instead of proving the EVM, the system could prove a different instruction set architecture (ISA), such as RISC-V or WASM in a new VM. Two projects that are working on these generalized zkVMs are RISC Zero and zkWASM. Let’s dive into RISC Zero a bit here to demonstrate how this strategy works and some of its advantages/disadvantages.
Risc Zero

RISC Zero is able to prove any computation that is executed on a RISC-V architecture. RISC-V is an open-source instruction set architecture (ISA) standard that has been gaining in popularity. The RISC (reduced instruction set computer) philosophy is to build an extremely simple instruction set with minimal complexity. This means that the developers at the higher layers in the stack end up taking on a greater load in implementing instructions using this architecture while making the hardware implementation simpler.
This philosophy applies to general computing as well, ARM chips have been leveraging RISC-style instruction sets and have begun to dominate the market of mobile chips. It turns out that the simpler instruction sets also have greater energy and die area efficiency.
This analogy holds pretty well for the efficiency of generating zk proofs. As discussed previously, when proving an execution trace in zk, you pay for the sum of the cost of all instructions per every item in the trace, so simpler and fewer total instructions is better.
How it works
From a developer’s perspective, using RISC Zero to handle zk proofs is much like using AWS Lambda functions to handle backend server architecture. Developers interact with RISC Zero or AWS Lambda by simply writing code and the service handles all the backend complexity.
For RISC Zero, developers write Rust or C++ (eventually anything that targets RISC-V). The system then takes the ELF file generated during compilation and uses that as the input code for the VM circuit. Developers simply call prove which returns a receipt (which contains the zk proof of the execution trace) object that anyone can call `verify` from anywhere. From the developer’s point of view, there is no need to understand how zk works, the underlying system handles all this complexity.

Pros
- Easy to use. Opens the door to any programmer to build zk applications
- Single circuit that provers can specialize for
- Also less surface area for attack, and less to audit
- Compatible with any blockchain, you just post the proofs
Cons
- Takes on a lot of overhead (in proof size and generation speed) to support such a generic interface
- Requires significant improvement in proof generation techniques in order to achieve broad support for existing libraries
Pre-built Reusable Circuits
For some basic and reusable circuits that are particularly useful to blockchain applications or elsewhere, teams may have already built and optimized these circuits for you. You can just provide the input for your particular use case. A Merkle inclusion proof for example is something that is commonly needed in crypto applications (airdrop lists, Tornado Cash, etc). As an application developer, you can always re-use these battle-tested contracts and just modify the layers on top to create a unique application.
For example, Tornado Cash’s circuits can be re-used for a private airdrop application or a private voting application. Manta and Semaphore are building an entire toolkit of common circuit gadgets like this that can be used in Solidity contracts with little or no understanding of the underlying zk moon math.
The Guide — Choosing your stack
As discussed at length, there are a myriad of different options for developing a zk application all with their own unique set of trade-offs. This chart will help summarize this decision matrix so that based on your level of zk expertise and performance needs, you can pick the best tool for the job. This is not a comprehensive list, I plan on adding to this in the future as I become aware of more tools coming up in the space.
zk App Dev Cheatsheet
1. Low-level Snark Libraries
When to use:
- You need fine control over the entire prover stack
- Want to avoid rebuilding common components
- You want to experiment with different combinations of proving schemes, curves, and other low-level primitives
When not to use:
- You are a novice looking for high-level proving interfaces
Options:
3. zk Compilers
When to use:
- Unwilling to take the overhead of a universal circuit
- Want to write circuits in familiar languages
- Need highly customized circuit
When not to use:
- Want to control the underlying cryptographic primitives
- Need a circuit that has already been heavily optimized
Options:
5. zkVM
When to use:
- Want to write code in high-level language
- Need to prove the correctness of this execution
- Need to hide some of the inputs to this execution from a verifier
- Have little to no expertise in zk
When not to use:
- In extremely low latency environments (it’s still slow)
- You have an enormous program (for now)
Options:
2. zk DSLs
When to use:
- You are comfortable picking up a new language
- Want to use some battle-tested languages
- Need minimal circuit size, willing to forego abstractions
When not to use:
- Need fine control over the proving back-end (for now, could interchange backends for some DSLs)
Options:
4. zkEVM
When to use:
- You have a dApp that already works on the EVM
- You need cheaper transactions for your users
- You want to minimize the effort of deploying to a new chain
- Only care about the succinctness property of zk (compression)
When not to use:
- You need perfect EVM equivalence
- You need the privacy property of zk
- You have a non-blockchain use case
Options:
6. Pre-built Reusable Circuits
When to use:
- You have a smart contract application that relies on common zk building blocks, like Merkle inclusion
- You have little to no expertise in the underlying zk stuff
When not to use:
- You have highly specialized needs
- Your use case is not supported by the pre-built circuits
Options:
Conclusion
zk is at the cutting edge of several technologies, and building it requires a profound understanding of mathematics, cryptography, computer science, and hardware engineering. Yet, with more and more abstraction layers available each day, app devs can leverage the power of zk without a Ph.D. As the limitations of proving times are slowly lifted over time via optimizations at all levels of the stack, we will likely see even simpler tools for the average developer.
I hope I convinced you, the curious software developer, that you can start using zk in your applications today. Happy Hacking!

Disclosures: Blockchain Capital is an investor in several of the protocols mentioned above. The views expressed in each blog post may be the personal views of each author and do not necessarily reflect the views of Blockchain Capital and its affiliates. Neither Blockchain Capital nor the author guarantees the accuracy, adequacy or completeness of information provided in each blog post. No representation or warranty, express or implied, is made or given by or on behalf of Blockchain Capital, the author or any other person as to the accuracy and completeness or fairness of the information contained in any blog post and no responsibility or liability is accepted for any such information. Nothing contained in each blog post constitutes investment, regulatory, legal, compliance or tax or other advice nor is it to be relied on in making an investment decision. Blog posts should not be viewed as current or past recommendations or solicitations of an offer to buy or sell any securities or to adopt any investment strategy. The blog posts may contain projections or other forward-looking statements, which are based on beliefs, assumptions and expectations that may change as a result of many possible events or factors. If a change occurs, actual results may vary materially from those expressed in the forward-looking statements. All forward-looking statements speak only as of the date such statements are made, and neither Blockchain Capital nor each author assumes any duty to update such statements except as required by law. To the extent that any documents, presentations or other materials produced, published or otherwise distributed by Blockchain Capital are referenced in any blog post, such materials should be read with careful attention to any disclaimers provided therein.










No Results Found.